
AI蓝皮书:从零开始了解本地AI部署(科普&Deepseek)
本教程为系列教程,旨在使用Windows系统搭建完善的NAS各项服务。应该是全网WINNAS系统性、完整性最强的教程。系列其他教程请BLOG内搜索“WINNAS轻松搭”或通过下方链接跳转:
1、硬件、系统+影视流媒体服务
从零开始搭建自己的流媒体服务器
EMBY媒体资源库进阶刮削方案
EMBY特殊影视资源刮削方案
2、音频流媒体服务(HIFI方向)
自建高音质流媒体服务器
3、漫画/小说平面媒体
自建在线漫画/小说库
4、DOCKER应用布置
各类AI大模型统一接口管理系统
5、娱乐相关
SillyTavern(酒馆)从入门到精通
6、AI相关
搭建本地AI(Deepseek)教程
AI大模型游戏/小说汉化(翻译)教程
喂饭:这里
一、前言
随着国产大语言模型Deepseek的发布,国内互联网也掀起了一股使用AI的高潮。但伴随着西方针对Deepseek上海机房的DDOS攻击不断加强,导致Deepseek官方API的可用性一言难尽。所幸Deepseek本身是开源的,任何人都可以在自己的电脑/服务器上进行布置。今天BLOG主就以Deepseek-R1模型为例,一边教大家如何自己布置一个大模型,一边展开聊聊AI大模型的入门知识。
二、安装Ollama
1、安装运行环境
需要运行AI大模型,首先我们需要在电脑上安装一个运行环境,当前主流的运行环境主要是Ollama和LMstudio,其中Ollama稍微复杂一些,所以我们用它作为例子。根据自己的操作系统,选择合适的版本下载安装即可。基本上没有需要特别注意的地方。
2、选择模型
安装完成后,我们可以打开Ollama的模型库,在这里有许多已经被收录的模型可供下载使用。我们很容易就看到Deepseek-R1模型,点击该模型页面,可以看到有以下多个模型规格可供选择。当然,Ollama的模型库收录的模型并不全面,特别是对小众的、新出的模型,很可能收录的比较慢。我们也可以自行到github上找相对的模型,下载到电脑之后再加载到Ollama上运行(有些github上的模型也提供了Ollama的运行命令,直接复制使用也行)。

我们可以看到从1.5b到671b不同的模型规格,实际上这里只有最大的671b模型才是真正的Deepseek-R1模型,其他几个则可以看做是由Deepseek担任老师,教育由“阿里巴巴的QWen”和“Meta的Llama”这两个模型学习后的高材生,这个做法,在AI领域被称作“蒸馏”。而模型名称中的 "1.5B"、"7B" 等数字指的是模型中参数量。这里的 "B" 代表 "Billion"(十亿),所以:1.5B 表示该模型拥有大约 15 亿个参数、7B 表示该模型拥有大约 70 亿个参数。
除了参数量外,还有一个关键影响是数据类型(量化参数),一般我们标记为FP32/INT8/INT4等,他们代表的是上述每个参数储存所需要占用的字节。我们平时还常见的Q4或者Q8量化,实际上指代的就是INT4或者INT8。
| 数据类型 | 占用字节 |
| FP32 | 4 |
| FP16/BF16 | 2 |
| INT8 | 1 |
| INT4 | 0.5 |
而所需要显存的计算公式则是:显存 (GB) = (参数量 * 每个参数的字节数) / (1024 * 1024 * 1024)。例如我们查看ollama页面下,deepseek-r1蒸馏的1.5b模型。
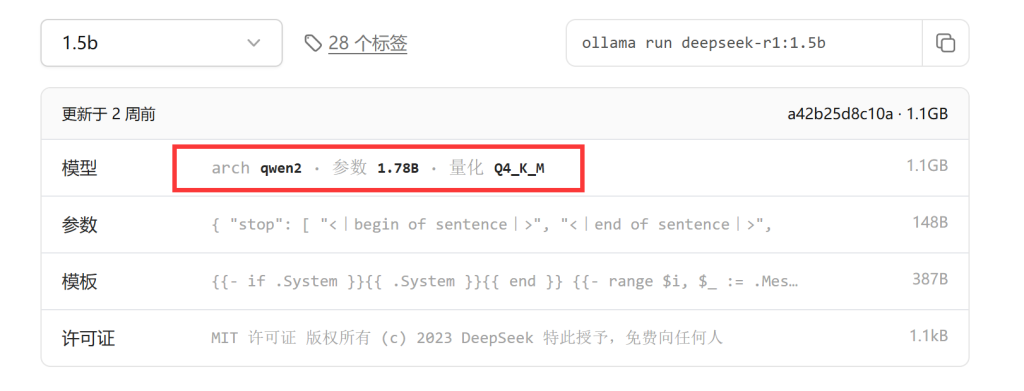
从标注看,接受训练的模型是来自阿里的Qwen大模型,模型总参数是1.78b,量化参数为Q4,通过上面公式,就可以算出:(1.78 * 10^9 * 0.5) / (1024 * 1024 * 1024) ≈ 0.83 GB。另外,上面我们看到的量化精度后面的"K_M",则代表的是它使用了某种混合策略,其中一部分权重以更高的精度存储,以减少量化带来的精度损失。 具体来说,"K" 和 "M" 代表不同的块大小或矩阵分解方法,用于更有效地存储量化后的权重。如果听不懂,用人话讲就是,模型中重要的地方储存精度更高一些,不太重要的地方,储存精度就低一些,这样混合储存可以有效提升模型的智商。所以,我们才会看到标注为1.5b的模型,其实际量化精度为1.78b,就是因为混淆策略所带来的。
但除了必须的0.83G显存开销之外,任何量化的模型其实都有额外的显存开销,因为它需要存储额外的元数据 (例如缩放因子、零点) 或更高精度的权重。这部分通常很难计算,我们一般动态地在原现存开销的基础上,预留20%-50%左右的显存即可。因此,Deepseek-R1蒸馏的1.5b模型,总需要现存范围是1G-1.25GB显存之间。
0.83 GB * 1.2 ≈ 1.0 GB
0.83 GB * 1.5 ≈ 1.25 GB
同理计算之后,我们就可以得知deepseek-r1各蒸馏模型所需要的显存了:
| 蒸馏模型 | 参数规模 | 所需显存 |
| Qwen | 1.5b(1.78b) | 1GB-1.25GB |
| Qwen | 7b(7.62b) | 4.26GB-5.33GB |
| llama | 8b(8.03b) | 4.49GB-5.61GB |
| Qwen | 14b(14.8b) | 8.28GB-10.35GB |
| Qwen | 32b(32.8b) | 18.32GB-22.91GB |
| llama | 70b(70.6b) | 38.48GB-49.35GB |
有人可能会问,如果我的显存不够大,那是否可以运行更大规模的模型呢?实际上是可以的,当前常见的方案有三种:
第一种是显存卸载(Offloading)技术,将模型的部分层或权重卸载到内存中。当需要使用这些层或权重时,再将其从内存加载到显存中进行计算。 这种方法可以在一定程度上减少显存占用,但会引入额外的 CPU 和内存之间的数据传输开销,导致运行效率降低。
第二种是模型并行(Model Parallelism)技术,将模型分割成多个部分,并将这些部分分配到不同的 GPU 上。 每个GPU只负责计算模型的一部分,从而减少了单个GPU的显存需求。 当前苹果的M4 Pro系列或者AMD的AI系列CPU采用的统一内存(Unified Memory Architecture, UMA)技术,让CPU和集成显卡(或GPU)共享同一块物理内存,可以更高效地在CPU、GPU和神经引擎之间传递数据。
第三种则是使用CPU进行推理,这种方法顾名思义,让模型直接通过CPU而非GPU进行加载和推理,理论上只要内存(而非硬盘)足够大,就能加载模型。 但是速度会显著降低。一般而言,CPU推理只适用于非常小的模型,或对性能要求极低的轻量化应用场景。 对于稍大一些的模型,即使能跑起来,性能也往往难以接受。
以上三种方案,都会影响到AI推理的效率,考虑到民用显卡本身就不算快,所以BLOG主建议还是应该全部加载到显存中运行为好。
3、下载和运行模型
3.1、Ollama官网提供的模型
OK,我们根据自己的硬件和上面的说明,选择好相应的模型后,接下来就可以下载和运行相关的模型了!如下图所示,点击选择好的模型右面红框中的复制按钮,复制这行命令。
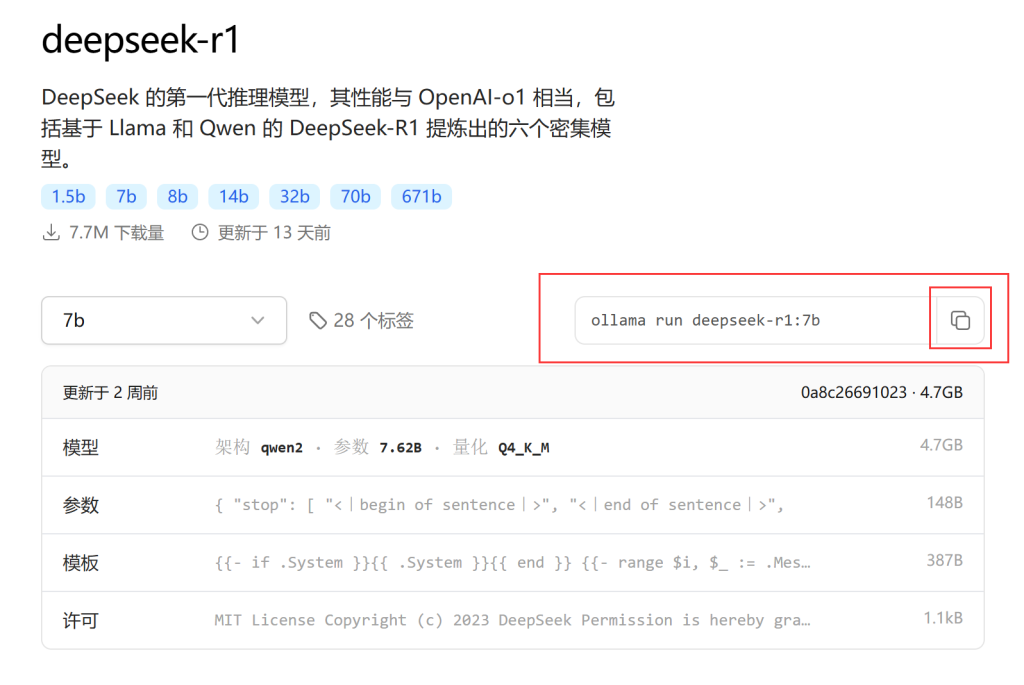
随后打开命令提示符,将命令输入进去,接着回车等待下载和运行即可。整个过程非常简单,如果出现报错,请检查网络(梯子)。
等待下载完成后,模型会自动运行,这时候只要保证Ollama主程序被打开(在桌面右下角看到图标)就行,这个CMD窗口可以关闭了。
3.2、导入第三方GGUF模型运行
如果遇到梯子不好使,或者Ollama官方没有收录的模型,这时我们可以在别的地方下载好模型本体,然后导入Ollama中运行。
首先第一步我们需要下载格式为“XXXX.gguf”格式的大模型,这里BLOG主作为例子,选择的是一个名为“sakura-1.5b-qwen2.5-v1.0-fp16.gguf”的大模型文件,这些模型大多数时候都可以在github中找到并下载。下载完成后,我们将文件放置到硬盘的目录中,BLOG主选择是是“C:\model\sakura-1.5b-qwen2.5-v1.0-fp16.gguf”路径。随后在该目录的地址栏上,直接输入CMD并回车,就会在这个路径下打开命令提示符。
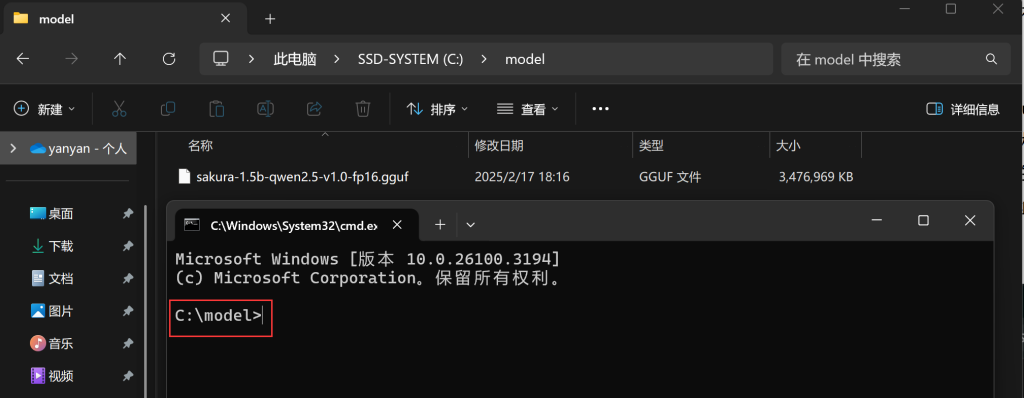
随后输入创建命令+模型名称,如:“ollama create sakura-1.5b-qwen2.5-v1.0-fp16.gguf”,等待创建模型完毕。我们随后可以通过“ollama list”命令来确认是否正确安装了该模型。
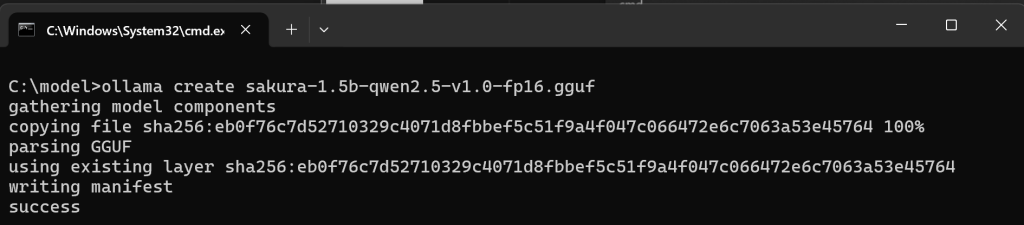

最后我们可以使用运行的指令,让模型加载,具体为运行指令+在list列表中实际显示的模型名称“ollama run sakura-1.5b-qwen2.5-v1.0-fp16.gguf:lateset”。
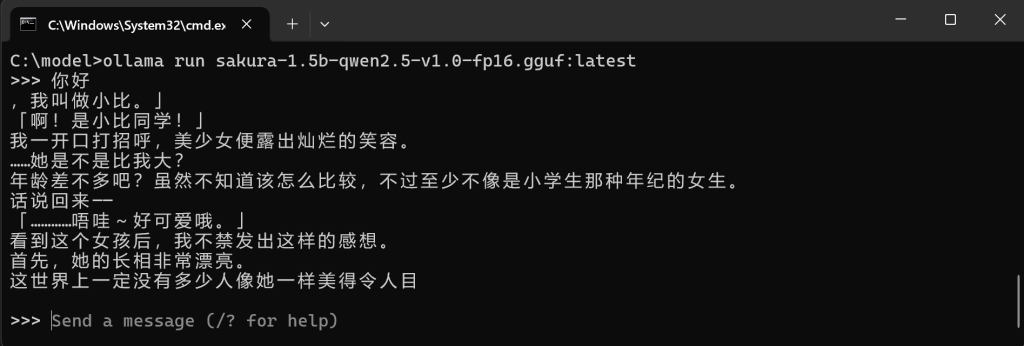
4、AI的应用场景
完成模型加载之后,我们就可以随意的使用这个不受限制的本地AI了。本地AI的应用场景有很多,比如之前BLOG主做过的使用AI大模型进行游戏游戏翻译。又或者最简单的,跟AI进行对话。这里BLOG主介绍一个AI对话的常见工具“Chatbox”
下载安装好Chatbox之后,运行程序。在左下角点击设置,模型提供方选择OLLAMA,API域名填写“http://127.0.0.1:11434”(注意,改路径为Ollama默认api域名,Ollama默认并不支持远程访问,仅限本地使用。且由于ollama没有提供api-key,因此暴露公网有较高风险。)模型选择刚刚下载好的模型,最后保存即可。
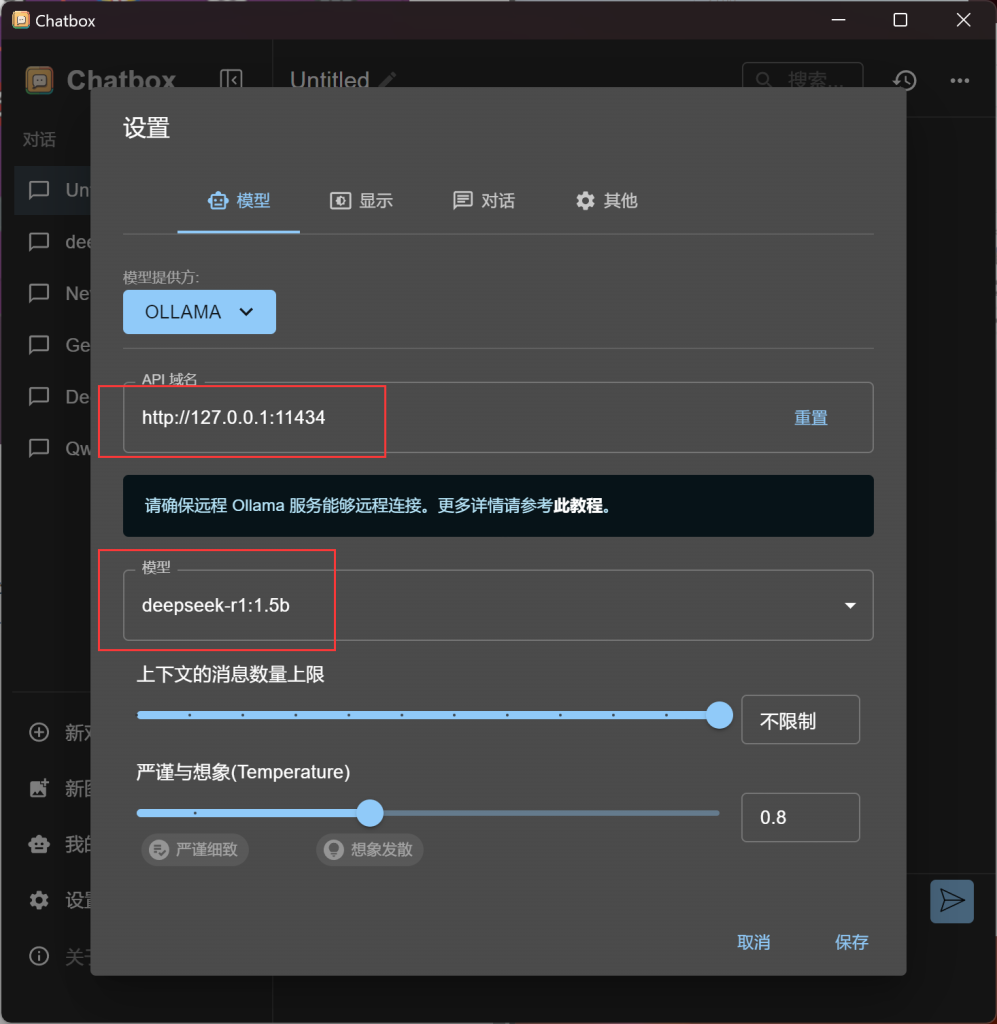
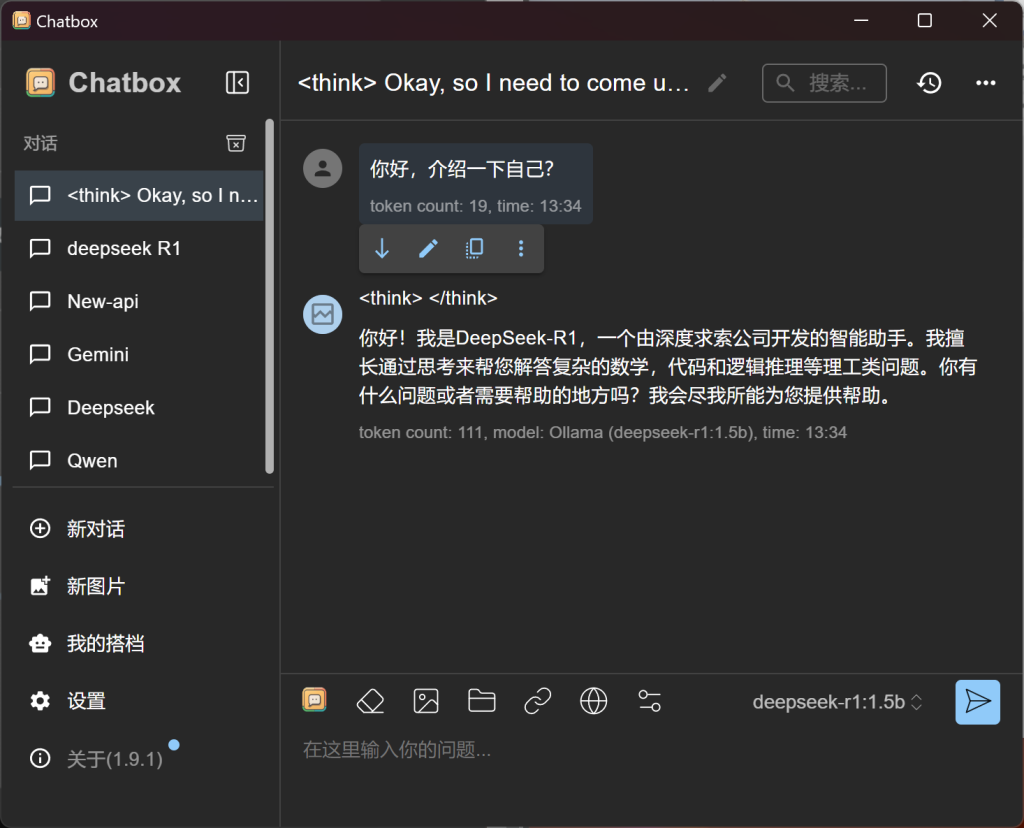
这里有两个选项可以解释一下:第一个是上下文的消息数量上限。 文字类大语言模型 (LLM) 有一个叫做“上下文窗口”或“上下文长度”的概念,它指的是 AI 在处理当前输入时,能够记住并利用的先前消息或信息量的限制。 简单来说,就是 AI 能够记住你之前说过的话的数量。对于本地模型,是否限制上下文长度取决于模型的配置和硬件资源。而温度(temperature)则是一个控制模型输出的随机性或创造性的参数,尤其是在文本生成任务中。高温会使输出更加随机和有创意,而低温则会使输出更保守和确定。





7条评论
Levi Gann
谢谢分享!
路过
网站feed链接失效了,
博主能修复一下么?
huoyanyan
我好像是顺手禁用了feed……我看看……额我已经重新启用了feed,但是不知道为什么不生效,尝试解决但是没能成功。
x
那个,农曆新年都过了,水仙的更新补丁还没做完吗?如果工作量大的话,其实不该说什麽时候会更新的
还有我在水仙那篇文说能不能把前三代汉化都摆上来没有被回复
ssss
blog 作为普通人日常生活中有什么需要用到本地部署的deepseek的地方吗
huoyanyan
自己想、自己开发、自己玩自己。
Taiki
其实现在本地算力不足导致实用性不强,这个时间就能弥补,未来模型肯定越来越高效,算力越来越便宜。
如果人人都能本地运行全功能的Deepseek模型,在我生活圈内,可以帮我完成很多公文,关于GCD的繁琐文件,工作总结和报告,搜索和筛选我想要的资讯。
另外,AI未来一个重要应用就是个人AI助手,相当于私人助理,解决你生活个工作上的各种杂事,这些都最好是本地部署的AI来完成,谁愿意把个人生活的数据连上网络?